Text-Social Benchmark¶
Tools¶
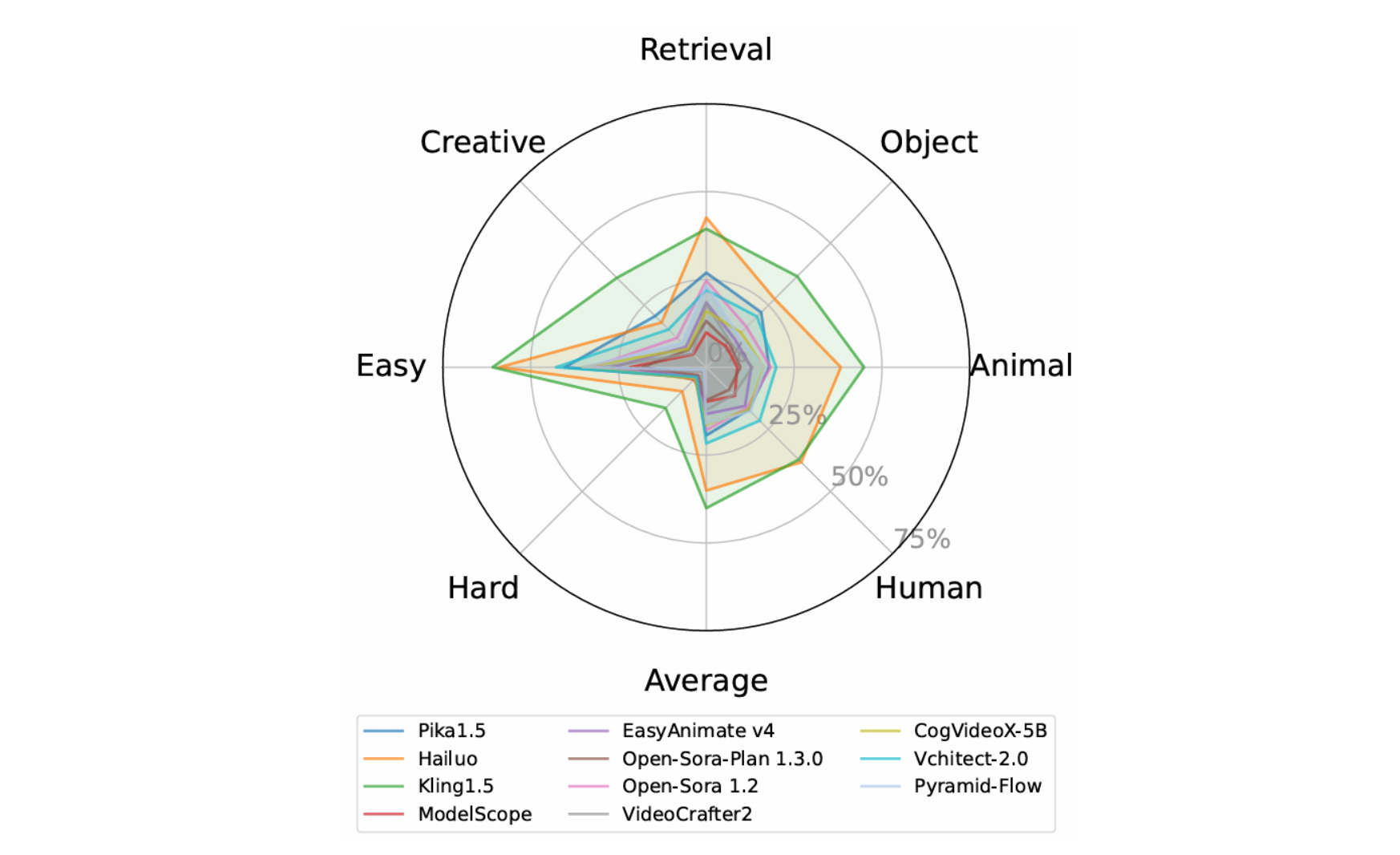
StoryEval¶
code: https://github.com/ypwang61/StoryEval
贡献:一个专门用于评估文本到视频(T2V)模型的“故事完成能力”的benchmark,专注于评估生成视频中连续事件的完成。
细节:会筛掉以面部表情作为事件的 prompt 数据,但 social 推理是需要面部表情的。
结果:Kling1.5和Hailuo 表现较好(闭源),Vchitect-2.0 也不错(开源)。(虽然没有考虑面部表情生成,但是结果仍有一定参考价值)
GPT-Image-1¶
链接:https://platform.openai.com/docs/models/gpt-image-1
价格有点小贵,只有Text2Image,无法生成视频(虽然现在多模态模型采样也是一帧一帧采,和读图片没有区别)。
BigToM¶
BigToM这个数据集比较有名气,24年出的现在引用量有130,而且论文里图画得很好看。
Causal Template¶

因果模型变量:
- Desires:“Noor wants to make a latte“
- Percepts/actions:“Noor fills a pitcher with oat milk“
- Belief:“Noor believes that the pitcher has oat milk“
- Causal Event:“oat milk“ → “almond milk”
如下是几种推理情况:
Initial Percept to Initial Belief :检验模型是否理解 Percepts(以及action)会引发Belief,即“Noor grabs a pitcher and fills it with oat milk“ → “Noor believes that the milk pitcher contains oat milk“
With vs. Without Initial Belief : 在 “without initial belief” 场景下,不明确揭示主体的 Initial Belief;在“with initial belief” 场景下则纳入主体的 Initial Belief,这会使推理变得更加容易,可跳过Initial Percept to Initial Belief 阶段。
Forward Belief :model 必须根据 agent 的 percepts of the causal event 来推断 agent 的 belief,推理可表示成 P (Belief | Percept)

Forward Action :model 必须根据 agent 的 percepts of the causal event 来推断 agent 的 action,这要求模型在根据 percepts 和 desire 来预测主体的行动之前,首先要推断出主体的belief。

Backward Belief :从观察到的 action 中推断 agent's belief . 这一情况非常困难,因为需要从观察到的行为中对未知的信念和感知进行联合推断。

Populating Causal Templates With Language Models¶
从 causal template 中创建 prompt 模板,并使用一个语言模型(GPT-4-0314,温度设置为 0.5 且采用默认参数)来填充模板变量。对于给定 prompt,利用3 few-shot examples 来生成3个new completions. 限制模型为模板中的每个变量准确生成一个句子。在此做一个假设 -- 该模型擅长进行 forward prediction,能够根据 context、 the belief and desire of the agen 想出合理的行动。
Composing Test Items from Template Variables¶
总体流程:

生成格式:

FANToM¶
目前很多 ToM 相关 benchmark 都缺乏人与人之间的交互,FANToM 旨在通过问答方式,在信息不对称的对话情境中对心理理论进行压力测试。
Information-Asymmetric Conversations :每段对话围绕一个主题展开,每个主题都有几个子主题。一开始,对话由两三个角色开启。随着对话的推进,有角色加入或离开讨论,并且对话的子主题也会随时间而变化。在某个角色不在场期间,对话会继续进行,其余参与者会分享信息,从而形成一种自然的信息不对称,这反映了现实生活中的互动情况。在一系列对话之后,之前缺席的角色(重新)加入对话,此时该角色并不知道之前其他参与者所分享的信息。
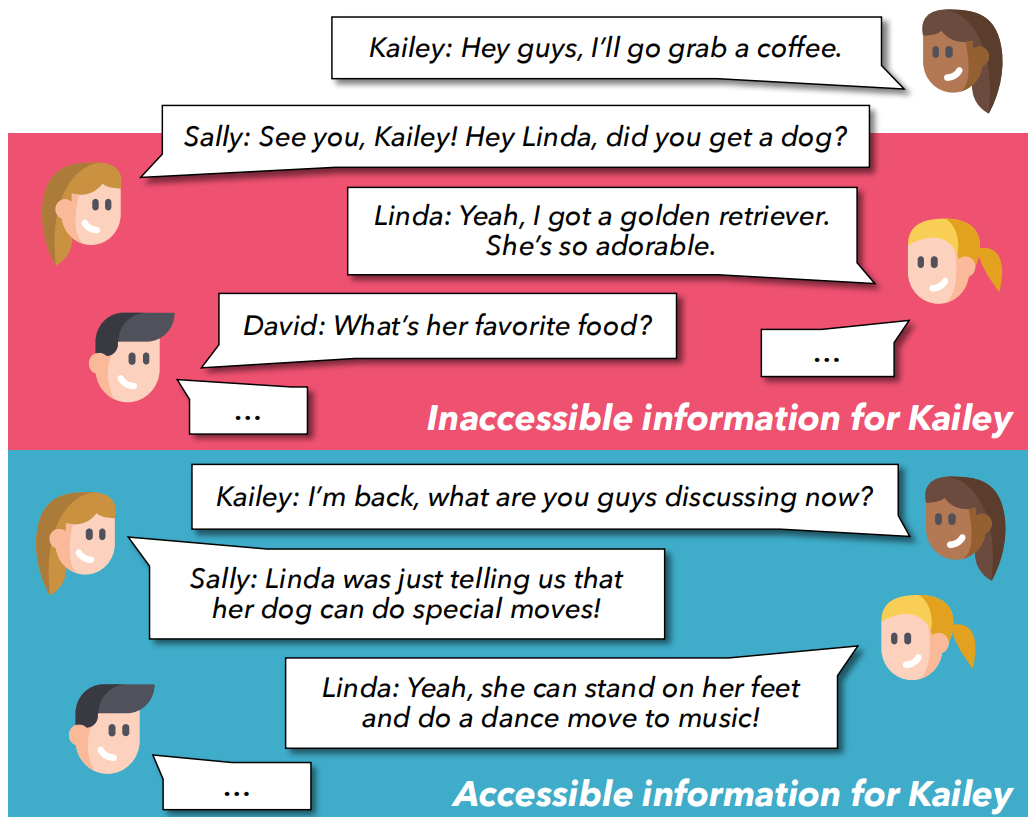
Factual Question-Answer (QA) Pairs :factual question-answer pairs (FACTQ) about the inaccessible information。对于每个 FACTQ,有两种不同类型答案:FULL FACT A & LIMITED FACT A
- FULL FACT A:包含了在 PersonX 缺席期间对话中的全部信息,X无法获取
- LIMITED FACT A : 仅依赖于Person X 参与的对话内容

ToM QAs based on Fact QAs : 对于每个 FACTQ,构建了六种类型的 ToM 问答对
- \(BELIEFQ [DIST.]\) & \(BELIEFQ [CHOICE]\) :通过对 FACTQ 进行重新措辞来询问对话中角色的Belief 而产生的。特别关注 Person X 对于其未参与的先前对话中无法获取的信息的 Belief。BELIEFQ [DIST.])要求 freez-form response。BELIEFQ [CHOICE] 针对同一个问题提供了多项选择选项,选项通过对 FULL FACT A(生成 Omniscient-view Belief) and LIMITED FACT A(生成 PersonX-centric Belief) 重新措辞生成

-
ANSWERABILITY Q[LIST] : Given the FACTQ, we ask models “ List all the characters who know the correct answer to this question”。关注模型是否能够识别出参与者中哪些人能够正确回答该 FACTQ。分两步:确定FACTQ答案,再找出能够获取的角色
-
INFOACCESS Q[LIST] : 将 FULL FACT A 与 FACTQ 一同提供给模型,并询问模型 “List all the characters who know this information”。旨在找出知晓或能够获取这条信息的角色。由于该信息已明确提供给了模型,所以只需要找出能够获取的角色。
-
ANSWERABILITY Q[Y/N] and INFOACCESS Q[Y/N] :要求模型通过简单二选一(Y/N)回答判断每个角色是否可以回答该问题,或者是否知晓相关信息

sample:



这个数据集只有对话,感觉不是很好生成视频。
OpenToM¶
Construction¶
每个story由两个主人公、一个目标实体(此后称为 “实体”)以及若干地点和容器组成。一个主人公被设定为 mover 对 entity 执行 action,另一个则为 observer,可能也可能没有目睹这些 action。
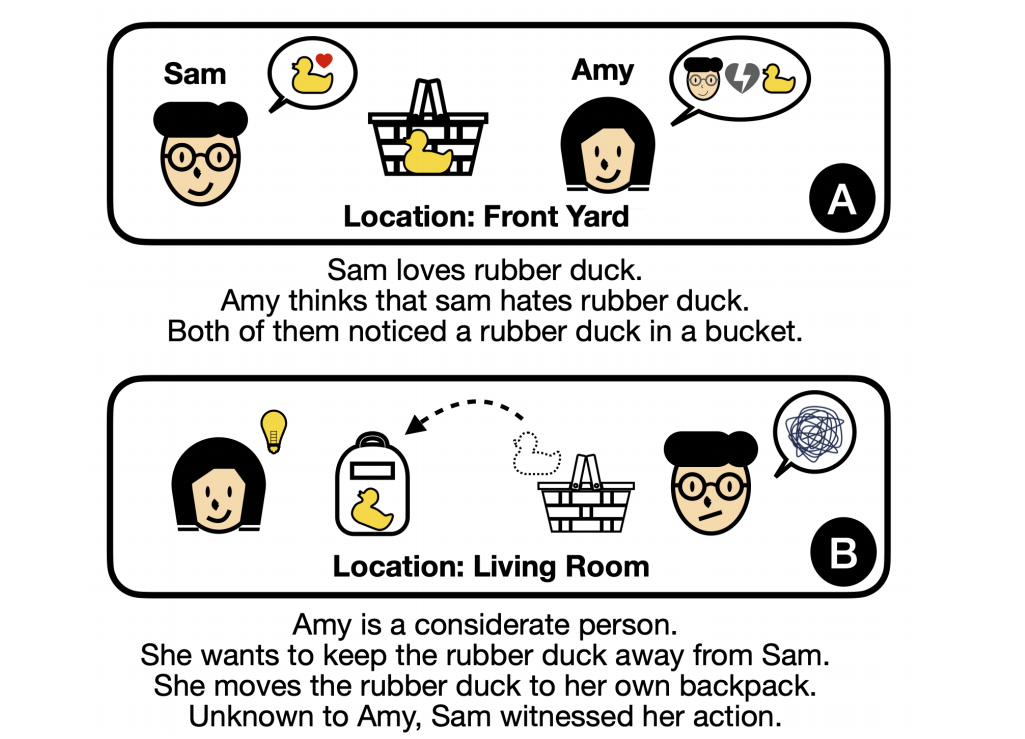
数据生成的两个过程:
- Character Personification Process :为每个角色赋予一种个性特征和个人偏好;从ToMi初始化世界状态,再促使GPT-3.5-Turbo 生成移动者的意图和行为。
- Narrative and Question Generation Process :一个 OpenToM plot 由三个段落组成。第一段阐述角色的个人偏好以及他们对彼此偏好的认知。第二段作为序幕,描绘初始的世界状态以及涉及两个角色的一些先前事件。最后一段描述主要事件,其中包括移动者的个性、移动者的意图以及他们随后的行动。明确纳入有关观察者是否察觉到移动者行动的信息,并将观察者的心理活动排除在叙事之外。

有故事线,而且有场景(多模态的话添加一些表情会更好?),个人觉得比较适合AI 生成,再人工/LLM给视频生成注解。
一些对比:

Limitations¶
- 由大语言模型生成的文本可能存在偏差,并且缺乏词汇多样性
- 角色情感方面的局限性:现实中,人类的情感往往是复杂且多面的,并且可能取决于一段较长时间内发生的多个事件。
- 线性叙事;未来的研究可以考虑构建具有非线性顺序的 OpenToM 叙事,以便进一步挑战大语言模型在叙事理解和 N-ToM 方面的能力。
ExploreToM¶
Story:不同角色对当前世界状态和其他人的 beliefs 有不同 beliefs
Question:探究模型理解能力
故事生成流程(一个完整的故事,T2V模型比较好生成?):

Plausible story context sampling :使用 LLM zero-shot 来生成连贯合理的故事背景,包括 character names, roles, locations, relevant objects, object containers, and discussion topics .
Theory of Mind-Specific Language Definition : 类似 RL 方法,且有多智能体联合; action set \(A\) , 每个动作会影响故事 state (Story state set \(S\) ) 和人物的 belief。 一个故事被定义为一系列的 action 及其影响(\(s=(a_1,...,a_n)\)),每个action 在应用时有前提条件。执行一个动作会自动更新对世界 state 的跟踪和对 belief 的跟踪. 支持的 action 范围有:物理改变世界状态&各种形式的交流。同时引入“Asymmetric belief updates”,对非对称信息场景进行建模(可以引入FANToM数据集,对其进行场景构建)
Generating Questions and Assessing Resulting Story Difficulty : 基于ExploreToM框架自动生成问答对。问题包括对中间状态的询问,拓展记忆类问题的复杂程度。包括二选一判断题和简答题。
A* Search :给定 Context C 和 actions A,需要找到具有挑战性的故事结构(实际上是actions该如何排列,会使得故事对LLM具有挑战性)。定义一个故事空间,每个结点都是一个story \(s=(a_1,...,a_n)\) , 只有s是s′的前缀,并且s′比s多包含k个动作时,s和s′之间存在一条边。采用 A* 算法,其会选择使 \(f(s)=g(s)+h(s)\) 最小的路径.
- \(g(s)\) 是从起始点到节点s的路径代价,量化为目标模型针对故事 s 的所有问题的准确率(越低越有挑战性,路径代价也就越低)
- \(h(s)\) 用于估计从节点s到目标节点(可以接受结束搜索的节点之一)的最便宜路径的代价。目标节点是那些满足isDesired(s′)=1的节点。量化为生成一个完整故事 \(s+s'\) 的可能性的近似估计。
- 所有的 \(s_i'\) 都是对 s 的随机采样延续,原算法要求评估 \(s\) 的所有邻居结点,探索空间巨大,不可行;预先设定固定数量邻居结点。
Story infilling :将带有故事背景C的完整故事结构 \(s=(a_1,...,a_n)\) 转化为听起来自然的叙述\(infill(a,z,d)\) : 根据某些风格方面的需求d,将每个动作a转化为一个听起来更自然的表述,并以上一步已填充的上下文z为条件. 迭代填充故事内容。
目前读到的最复杂的一个 story 生成算法,生成的故事看起来比较连贯,为了发论文也是不容易。